

コンバージョントラッキングのいちばんの功績は、「成果を可視化する」ためのコストを劇的に下げたことではないだろうか。
インターネット広告にはテレビのような大がかりな認知度調査は基本的にいらないし、数週間後ではなくほぼリアルタイムにクリックやコンバージョンといった実績を確認することができる。どの経路からどれくらいの反応があったかも一目瞭然。とても便利でわかりやすい。
便利でわかりやすいものは、そうでないものよりも投資しやすい。可視化のコストが低いということは、小さなトライを早くたくさん積み重ねられるということだ。その結果、インターネットはこれまで広告が出せなかった企業にも裾野を広げ、広告主の数を増加させることに成功している。
現在では、もはや存在しない世界を想像するほうがむずかしいほど、広告主は当たり前のようにコンバージョントラッキングを利用している。広告を配信することとコンバージョンを計測することはほぼイコールなのではと感じるほどだ。
コンバージョンは広告システムの「前提」
ほぼイコールということは、コンバージョントラッキングはもはや「計測」のみならず「前提条件」だといえるかもしれない。
モダンな広告プラットフォームのほとんどは入札やターゲティングが自動化されているし、動的な広告クリエイティブやレコメンデーションなども当たり前のように実装されている。これらの自動化機能のほとんどは、コンバージョントラッキングによって成果が可視化できている前提の営みである。根拠があるからこそ、止めたり踏んだりできるのだ。(逆にいえば、見えないものは止めたり踏んだりはできない)
「コンバージョンが正しく計測できている」ことは、インターネット広告の前提であり土台だと言い換えることもできる。おおげさにいえばコンバージョントラッキングは広告の生命線なのだ。
「可視化」の土台が揺らいでいる
でも、ご存知のとおり、その生命線はここ数年でかなりあやうい状況にあった。
携帯電話やスマートフォンの普及によるデバイスの分断にはじまり、昨今のプライバシー保護やサードパーティクッキーの規制などによって、コンバージョンの計測環境は長いあいだずっと揺らいできた。一時は危機的な状況だったと言ってもいいかもしれない。
もちろん、Google に代表されるプラットフォームもこれまでのやり方では測れないことは分かっているので、タグの更新によるサードパーティのファーストパーティ化や、自社データをプラットフォーム側に送ることで精度を高めるコンバージョン API の推奨など、ここ数年で急速なアップデートを行なってきた。
広告の生命線を維持するために必死だったのだ。
モデル化されるコンバージョン
詳細を挙げていくとキリがないので省くけれど、とにかくいろんな事情によってコンバージョン計測は日々むずかしくなっている。
でも、しつこいけどコンバージョン計測はインターネット広告の生命線だ。 あらゆるモダンな広告システムは「コンバージョンが正しく計測できている」という前提に立って設計されている。望むと望まざるとにかかわらず「これができないと成立しない」というレベルで、エコシステムに組み込まれているのだ。
そして、しつこいけど世の中はどんどん計測しにくい方向に進んでいる。このベクトルは不可逆で、一連のコンバージョンパスはいろんな理由でつながらなくなる。これからも分断することはあっても、つながることはないだろう。
計測ができる前提のシステムなのに、計測はしにくいのだ。アンビバレンツな状況!
計測できないとなると、推定していくしかない。測ろうとしてもつながらなくて欠損扱いになってしまうけれど、それが実際には存在していたと証明する(あるいはみなす)ことで、過小評価や間違った共有を避けないといけない。
であれば、関連性があって証拠の断片が残っているコンバージョンパスは機械学習によって結びつけてみたらどうだろう。そういう活動はこれまでも行われてきた。
その活動を「コンバージョンモデリング」という。
たとえば Google。コンバージョンはつねに小数点以下の値を持っている(「コンバージョン数:1.5 件」とかありますよね)。なんで整数じゃないのかといえば、1 件の貢献度を2つ以上のタッチポイントに割り振ったら 1 を下回るからである。
現在のコンバージョン貢献度のカウント方法は「データドリブンアトリビューション」がデフォルトになっているが、データドリブンというのは、要するにコンバージョンの貢献度をさまざまなタッチポイントにシステムが自動的に割り振るということだ。これは、コンバージョンに至るまでの経路(パス)をシステムが認識できている前提でないと成立しない。
コンバージョンの欠損を補うことは、経路を結びつけることでもあるのだ。
コンバージョンはどのように推定されているか
では、この結びつける作業はどのように行われているのだろうか。その方法をざっくりと解説したものが Google のヘルプページで公開されている。それがこちら↓
この公式ヘルプを読めば、仕組みは一目瞭然である。
ただ、せっかくここまで前置きをだらだらと書いたので、ついでに以下の段落で少しだけ補足というか、コメントを加えていきたい。お時間ある方はお付き合いください。
コンバージョンモデリングの仕組みについて
モデリングがどのように行われている(&使われているか)を端的に示したのが以下の図になる。
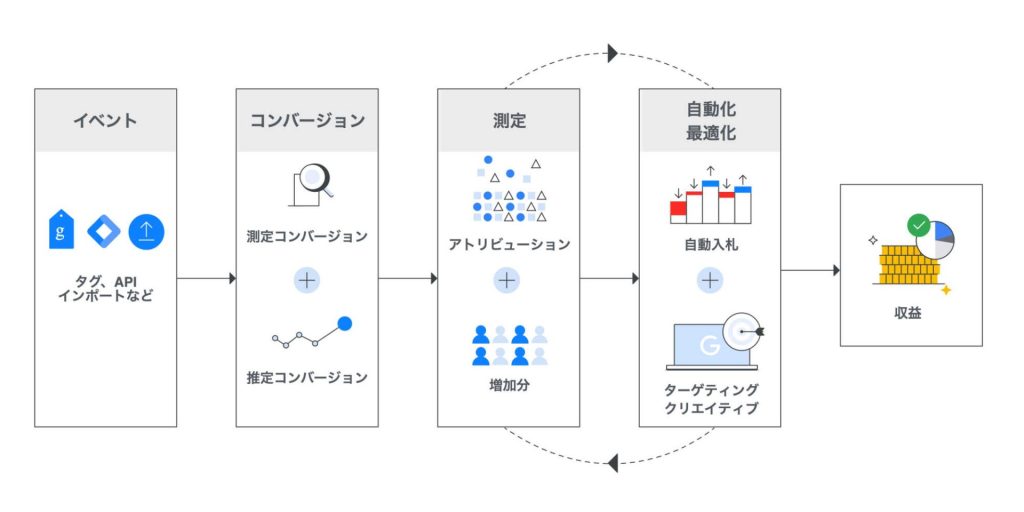
この図にあるとおり、コンバージョンモデリングにまつわる作業を段階で示すと、「イベント」→「コンバージョン(分類)」→「測定」→「自動化・最適化」となる。
タグやインポートなどによって計測されたコンバージョンイベントは、「測定コンバージョン」と「推定コンバージョン」の2つに分けられ、それぞれが連関しているのか/そうでないのかを見極めて、貢献度が振り分けられ、可視化されていく。
貢献度が振り分けられたあとは、入札やターゲティングなどに活かされていくことで最適化や最大化が進み、めぐりめぐって収益の増大につながるというわけだ。
イベント
まずは図のいちばん左の「イベント」から見ていこう。
コンバージョンイベントについては参考になる記事が山ほどネットにあるので詳細は割愛するが、とにかくいろんなかたちでの実装が可能だ。
伝統的に行われているサンクスページのページビューをもって発火する、という形式のみならず、SPA のような URL が置き換わらないパターンに合わせたイベント識別子の取得や、アクセス解析データからのインポート、拡張コンバージョンのようなAPI での接続など、いろんな形式でコンバージョンは入力できるようになっている。
こうして集められたデータは、次のコンバージョンデータの振り分けへと進んでいく。
コンバージョン(の分類)
「コンバージョンが欠損する」という言葉があるが、それは発生したコンバージョンの中にそれまでのアクションと結びつけられない(結びつけにくい)ものがあるがゆえに管理画面やレポートに現れないという意味のことだ。
たとえば、デバイスまたぎによるコンバージョンパスの分断や、Apple のATT(App Tracking Transparency)や ITP(Intelligent Tracking Prevention)などによって、コンバージョンのタグ自体が発火しても、それまでのパスが切られているのでどのアクションに基づいて発生したかは不明瞭になってしまう。
それを明らかにするために、まずはつながっているコンバージョンと、つながっていないコンバージョンとを分けて整理するのがこの段階だ。
どこにも属さないコンバージョンは可視化されないので、存在しなかった(=ゼロ)ことになってしまう。実際にあったコンバージョンも、クリックやインプレッションに紐づかなければ残念ながら管理画面の中に居場所はない。そういった不幸な事態を避けるために確からしい推定を行うための前処理として、コンバージョンを分類する。
具体的な動きを見てみよう。コンバージョンはカウントの段階で以下の2種類に分けられる。
| 測定コンバージョン(Observed) | 推定コンバージョン(Unobserved) |
|---|---|
| Cookie およびその他の識別子を使用して、広告インタラクションとコンバージョンを関連付けられたもの | 測定コンバージョンに至らなかったもののうち、機械学習を活用して広告インタラクションとコンバージョンを結びつけたもの |
「測定コンバージョン」はインタラクションとコンバージョンが結び付けられたもの。つまり普通に問題なくカウントできたコンバージョンのことだ。一方の「推定コンバージョン」はコンバージョンに帰属するクリックのようなインタラクションが見当たらなかったものである。

測定
そして、測定されたコンバージョン群(=インタラクションとの結びついて一連のコンバージョンパス)は、そこからまた複数のサブグループに並べ替えられる。サブグループのキーになるのは、時刻や場所、デバイスや OS の種類などのシグナルが使われる。
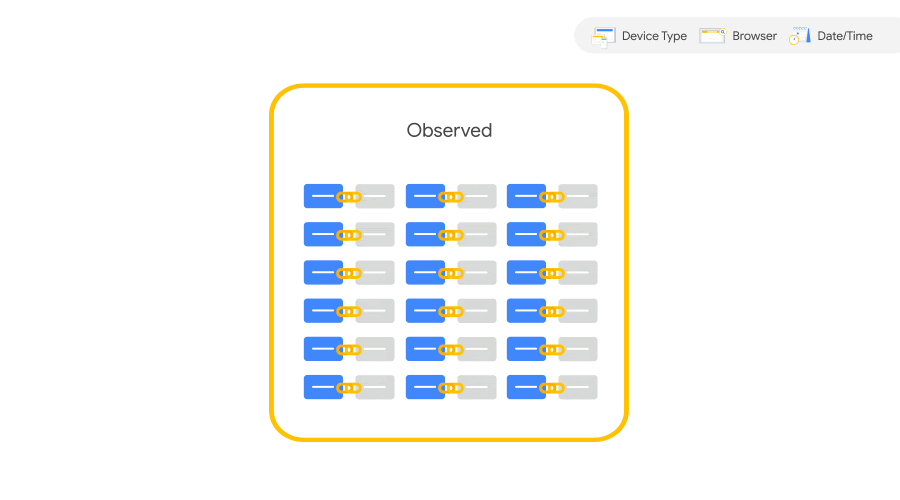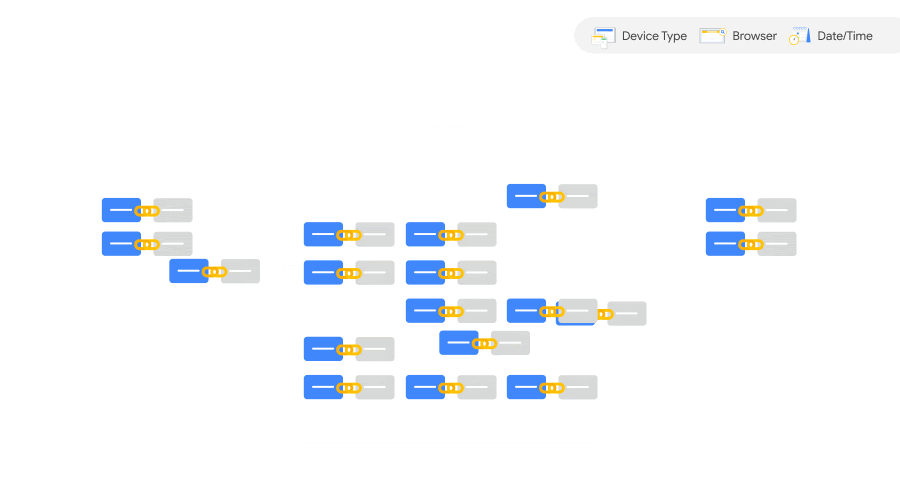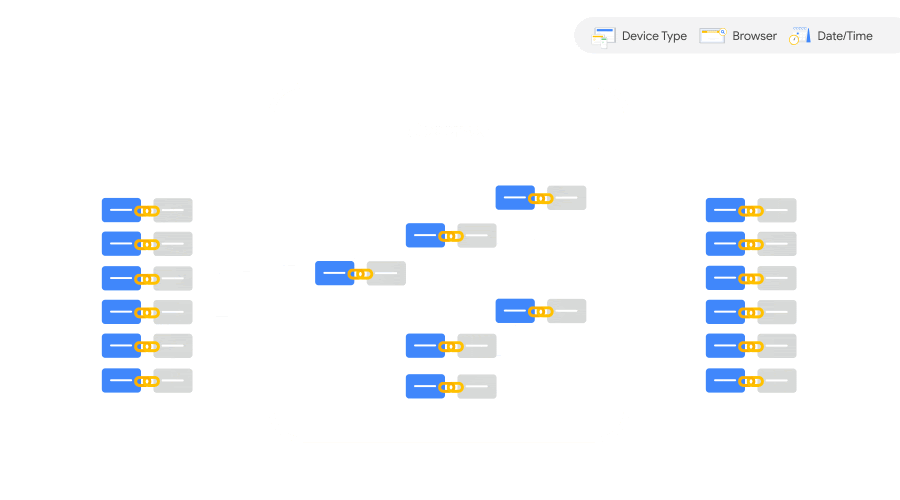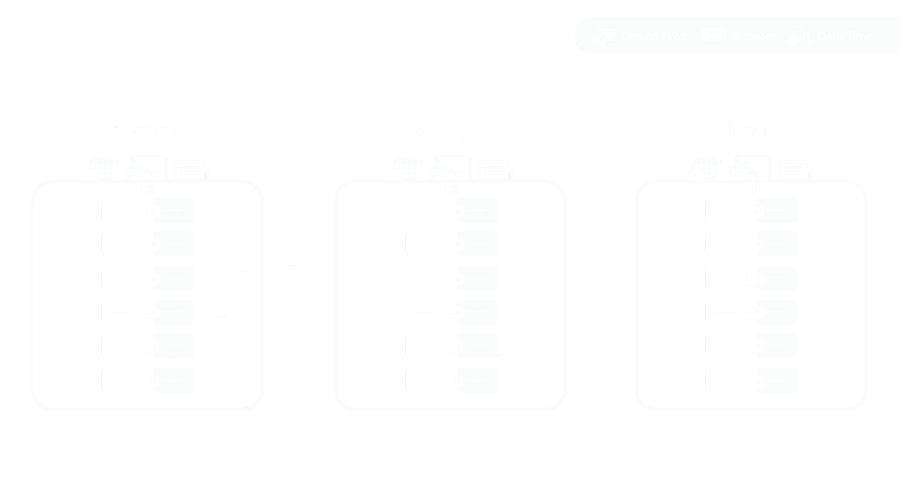
そして、最初の段階でインタラクションとコンバージョンが結びつかなかった推定コンバージョン(図の Unobserved)は、測定コンバージョン(図の Observed)のサブグループの持つ基準にアラインさせるかたちで整理される。
サブグループの分かれ方(時刻や OS などのシグナル)が、途切れたコンバージョンをつなげる重要なヒントになるのだ。

こうした整理が繰り返し繰り返し行われながら、機械学習によって徐々に精度を増していく。
もちろん、やみくもにインタラクションとコンバージョンを紐付けないように(つまり過剰なコンバージョンカウントにならないように)、機械学習のベストプラクティスとされるホールドバック検証(※) によって精度は維持されている。あくまで広告がコンバージョンにつながったと強く類推できる場合にのみ、コンバージョンの合計に含まれる。
※ Holdback Validation: 元データをランダムに「訓練セット」と「検証セット」に分けて行う方法。影響する要素をぞれぞれ層別サンプリングに基づいて検証するため、純粋なランダムサンプリングに基づく検証よりもバランスが優れているとされている
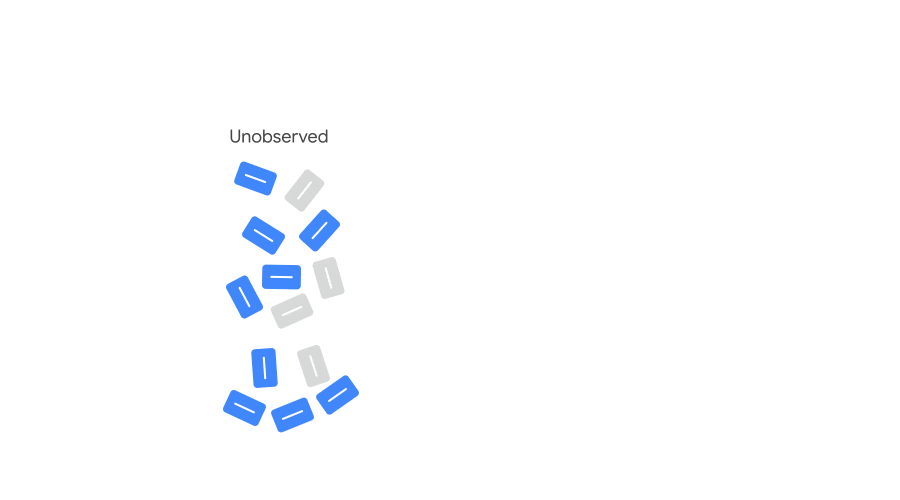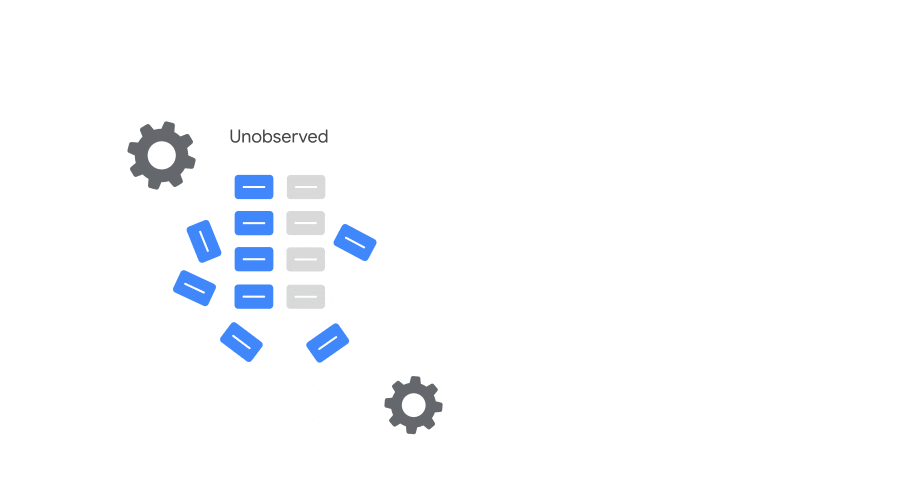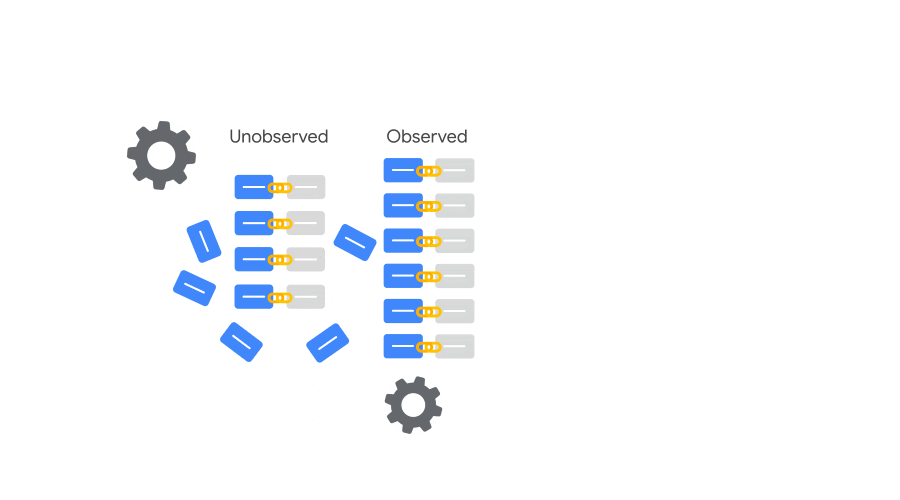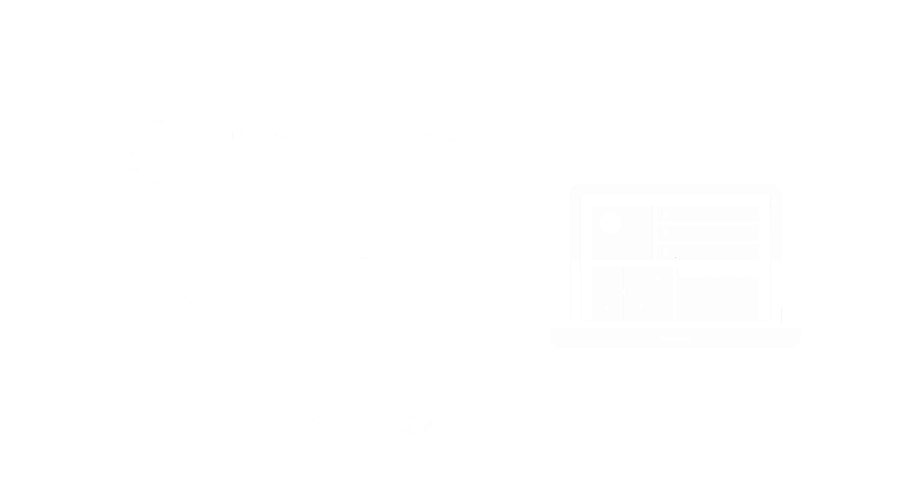
インプレッションやクリックといった広告のインタラクションと、帰属する元が見つからなかったコンバージョンアクションを機械学習によってリンクさせる。この一連の作業が「コンバージョンモデリング」である。
ここまで見てきたように、モデリングは、コンバージョンがどのアクションやソースに帰属するかを明らかにする行為でもある。単にカウントできていればいい、というわけではない。
自動化/最適化
こうしてモデル化されたコンバージョンデータは、自動入札の根拠として取り込まれていき、最適化/最大化へと使われていく。
直接データをつなげるのが難しくなればなるほど、さまざまなディメンションにもとづく類推の重要性は増すことになる。そして、これらのコンバージョンパスデータを効率よく獲得する手段として
- 学習機会の担保:マッチタイプの柔軟性、ターゲティングの自動化、予算の許容範囲の拡大など
- データソースの多様化:APIやアップロードによるリンク、プラットフォームが持つ類似のデータセットの利用、外部データとの連携など
の2つが強く推進されていく。モデルを強化していくためだ。(プラットフォームの営業さんがこの2つしか言わないのもこれが理由です)
モデル化されたコンバージョンを根拠に動くインターネット広告
ここでは Google 広告を例に挙げたが、多くの広告プラットフォームはコンバージョンモデリングを前提にシステムが設計されている。
こうして自己増殖していくシステムだからこそ、不況下やコロナ禍であっても売上を伸ばしつづけることができたのだろう。ITP や ATT、それを後押しするようなプライバシー保護の流れによって荒れ吹く逆風もなんのその、モデル化された成果を学習の根拠として、この瞬間も拡大をつづけている。
コンバージョンモデリングという推定技術は、データのギャップを解消することと、個人を特定しないプライバシー保護とを両立している。欠損がなくなったコンバージョンは、入札をはじめとした自動化戦略をレバレッジさせる役割としてこの両立をさらに強化する。
プラットフォームの多くはサードパーティクッキーの終了に備えて拡張コンバージョンのような広告主にファーストパーティデータを提供するプログラムを強く推進している。コンバージョンモデリングの精度は、そのまますなわち彼らのビジネスの成否につながるからだ。やはり、コンバージョンは広告の生命線なのである。
なお、ここでモデリングそのものの良し悪しは問わない。いいとかわるいとかの話ではなく。欠損がある状態が続くと誤ったデータをもとに意思決定することになるので、広告主にとってもパブリッシャーにとっても不利益が大きくなってしまう。だからモデリングは必要だ。善だと思うか必要悪だと思うかは、その人の立場によるだろう。
課題があるとすれば、モデル化の方法に外部のレビューが入りにくいことと、自動入札を強制することがプラットフォームの収益の柱になっている以上、レビューへのインセンティブが生まれないことだろうか。
主体の善性に頼るしかない仕組みは、長期的に見れば脆弱だと思うのだ。

